對比學習在CV與NLP領域的研究進展與技術發展
對比學習作為一種自監督學習方法,近年來在計算機視覺和自然語言處理領域取得了突破性進展。它通過拉近相似樣本、推遠不相似樣本的方式學習數據的表征,顯著提升了模型在無標注或少量標注數據上的性能。
一、計算機視覺領域的研究進展
在CV領域,對比學習最初通過SimCLR、MoCo等框架展現了強大潛力。SimCLR通過數據增強構建正樣本對,利用NT-Xent損失函數進行優化;MoCo則引入動量編碼器和動態隊列,穩定了負樣本的對比過程。BYOL和SimSiam進一步探索了無需負樣本的對比學習范式,通過預測頭架構和停止梯度操作避免了模型坍塌問題。這些方法在ImageNet等基準數據集上取得了與監督學習相媲美的性能,并推動了目標檢測、語義分割等下游任務的進步。近期研究聚焦于多模態對比學習(如CLIP),通過圖像-文本對訓練實現零樣本泛化能力,極大拓展了應用邊界。
二、自然語言處理領域的技術演進
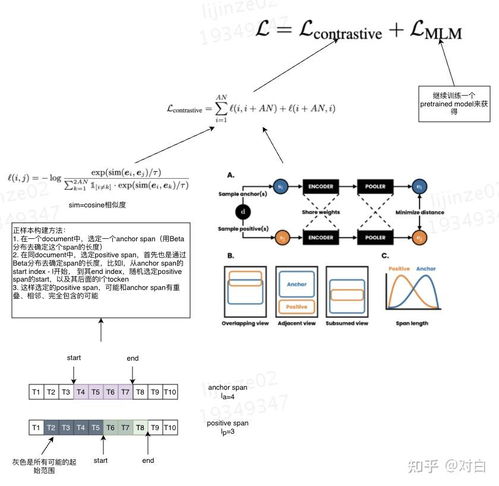
NLP領域早期通過Word2Vec的Skip-gram模型隱含了對比思想,而真正突破始于SimCSE和BERT對比學習變體。SimCSE通過Dropout噪聲構建句子級正樣本,顯著提升了語義相似度計算效果。InfoWord、DeCLUTR等工作則針對詞、句級別表征進行對比優化。關鍵進展體現在:1)結合掩碼語言建模的混合預訓練策略(如ELECTRA);2)跨模態對比學習(如VisualBERT),對齊視覺與語言表征;3)提示學習與對比結合,提升小樣本場景性能。當前,對比學習已成為提升預訓練語言模型魯棒性和語義理解能力的重要手段。
三、核心技術創新與試驗發展
- 負樣本處理技術:從大規模負樣本隊列(MoCo)到基于聚類的原型對比(SwAV),再到完全消除負樣本的方法,研究者不斷優化計算效率與表征質量平衡。
- 損失函數設計:InfoNCE損失成為主流,其溫度參數調節成為研究熱點;Triplet Loss、Circle Loss等變體針對困難樣本優化。
- 數據增強策略:CV領域依賴裁剪、色彩抖動等圖像增強;NLP領域則探索回譯、詞替換等文本增強方法,但文本語義保持仍是挑戰。
- 理論突破:對比學習與互信息最大化的理論聯系被深入探討,最近的研究揭示了梯度一致性與表征坍縮的內在機制。
- 跨領域融合:多模態對比框架(如ALIGN)通過數十億級圖像-文本對訓練,實現了開放域理解能力的飛躍。
四、挑戰與未來方向
盡管成果顯著,對比學習仍面臨諸多挑戰:1)對數據增強的高度依賴限制了領域適應性;2)負樣本在高度相似場景中的判別困境;3)計算資源消耗巨大。未來趨勢可能包括:
- 輕量化對比框架設計,降低計算門檻
- 結合因果推理提升表征可解釋性
- 探索量子化對比學習等新型優化范式
- 在醫療影像、科學文獻分析等垂直領域的深化應用
對比學習通過不斷創新的技術路徑,正在重塑CV與NLP領域的表征學習范式。隨著理論體系的完善與跨學科融合的深入,其有望成為通向通用人工智能的關鍵基石之一。
如若轉載,請注明出處:http://www.coston.cn/product/70.html
更新時間:2026-02-15 03:33:34